Les bases de données¶
BDIR¶
Base de Données Indexation Recherche accessible à partir de dga12 et dgaprod.
En cas de problème sur la BDIR, contacter ctig.systeme@dga.jouy.inra.fr
Une BDIR est une Base de Données Indexation Recherche : « Réunir autour d’une base de données unique, structurée et documentée l’évaluation génétique, la validation et l’exploitation des résultats ainsi que les travaux de recherche portant sur les données du contrôle de performances en ferme (état-civil, généalogie, contrôle laitier, contrôle de croissance, insémination, morphologie, données moléculaires). Cette base de données sera l’unique interface entre d’une part les systèmes nationaux de gestion des données zootechniques (SIG pour les bovins, SIEOL pour les ovins laitiers, SIECL pour les caprins, OVALL pour les ovins allaitants) et d’autre part les activités d’évaluation génétique et de recherche »
On parlera de plusieurs Bases de Données Indexation Recherche.
Une BDIR est une base de données qui contient :- des fichiers issus des systèmes nationaux de gestion des données. Ces fichiers servent de base à l’évaluation génétique
- les résultats des calculs d’évaluation génétique
- les paramètres des calculs génétiques (héritabilités, corrélations génétiques, autres paramètres des lois de distribution des variables) utilisés
- les valeurs génétiques diffusées
C'est un infocentre : les données de référence restent dans les systèmes d’informations nationaux.
Une BDIR correspond en général à un champ zootechnique :- indexation des ovins laitiers
- indexation des bovins laitiers
- indexation des caprins ...
On fait donc par exemple référence à la « BDIR Bovins allaitants ».
Données¶
La documentation sur les droits d'accès peut être demandée à ctig.systeme@dga.jouy.inra.fr.
Pour toute demande d'accès, contacter :- BDIR bovins(/bdir/bovins/) : Vincent.ducrocq@jouy.inra.fr ou eric.venot@jouy.inra.fr ou didier.boichard@jouy.inra.fr
- BDIR caprins(/bdir/caprins/) : helene.larroque@toulouse.inra.fr
- BDIR ovins(/bdir/ovins/ : laurence.tiphine@idele.fr
- BDIR porcins(/bdir/porcins/) : thierry.tribout@jouy.inra.fr
Voir la partie cadre technique pour les descriptions techniques de l'organisation des données en bdir.
Les outils mis à disposition sont disponibles depuis toutes les plateformes qui accèdent aux BDIR.
Suppression et Archivage¶
Principe de base
(MAJ 17/11/2015) Ne s'applique pas aux données dans /bdir/bovins/ibl/donnees_valogene
(MAJ 18/08/2017) Ne s'applique pas aux données dans /bdirgeno/bovins/
Les BDIR non officielles sont conservées 6 mois en ligne, puis supprimées.
Les BDIR officielles sont conservées 3 ans en ligne, puis supprimées et archivées pendant 7 ans : le délai de conservation total est donc de 10 ans.
Qu'est-ce qu'une BDIR officielle ?
- Les 3 BDIR bovines laitières par an donnant lieu à une diffusion officielle des index (les évaluations génomiques mensuelles ne sont donc pas considérées comme officielles)
- Les 3 indexations annuelles interbull
- Une BDIR bovins allaitants par an et par race
- La première BDIR de chaque trimestre pour les porcs
- Les 3 indexations caprines annuelles (il existe 2 indexations vraiment officielles, et une qui est faite pour les OS, mais on souhaite garder cette dernière également plus de 6 mois)
- Les évaluations mensuelles ovins allaitants
- L'évaluation ovins allaitants scice (une cinquantaine par an)
- Les 4 évaluations ovines laitières
Finalement, on peut définir une BDIR officielle comme un traitement que l'on souhaite conserver plus de 6 mois ...
Le CTIG fait un point tous les 6 mois pour appliquer les règles d'archivage et de suppressions.
L'archivage suit l'organisation bdir, par exemple on ne trouvera pas directement la bdir correspondant à l'indexation charolaise 2012 mais les répertoires correspondants (donnees_bn, retour_ferme, retour_diffusion, ..)
Faire la demande à ctig.preparation@jouy.inra.fr pour récupérer une archive
BDIR donnees_valogene
(MAJ 17/11/2015)> Pas d'archivage : on garde tous les traitements sur disque jusqu'à la mise en place du projet BDIR_PHASES
Explication : une BDIR s'effectue sur le delta des données par rapport à la dernière BDIR. Toutes les BDIR sont donc complémentaires et aucune ne peut être supprimée.
(MAJ 18/08/2017)> BDIR_PHASES a été mis en place au printemps 2016, le répertoire donnees_valogene devrait être amené à disparaitre
(MAJ 18/08/2017)> BDIR Génomique bovine (/bdirgeno/bovins/)Les traitements désignés comme étant officiels sont :
- le dernier traitement de juin
- le traitement de décembre
Pour les années N à N-2 : sont conservés sur disque les 2 traitements officiels
Pour l'année N : sont en plus conservés les 3 derniers traitements (officiels ou non-officiels)
Il n'y a donc aucun archivage ADA pour ce type de BDIR, uniquement de la sauvegarde sur disque.
BDIR Compléments
On peut souhaiter stocker en bdir des données complémentaires : image du SIG ayant servi à l'extraction des données, données de calcul intermédiaires au format SAS, donnée en entrée pour la sam ou interbull, phases, bilans PDF de covalidation, commentaires, etc...
Ces données qui ne répondent pas aux normes techniques de la bdir (fichier csv, tabulaires et documentés) peuvent être mis en BDIR mais obligatoirement dans un sous-répertoire /complements qui se trouvera en aval des répertoires identifiants une bdir (ce sous-répertoire a donc les mêmes droits d'accès que la bdir dans laquelle il est placé), par exemple :- /bdir/bovins/ibl/retour_poly/ t1220 /lait/r56/complements/ ou /bdir/bovins/ibl/retour_poly/ t1220 /lait/complements/
- /bdir/bovins/iboval/retour_diffusion/ cha_2012_01 /complements/
- /bdir/bovins/iboval/donnees_bn/ ex_2010_12_17 /complements/
Sous le répertoire /complements, l'indexeur peut organiser l'arborescence qui lui convient
Attention! il ne s'agit pas de mettre tous les fichiers de travail dans le sous-répertoire compléments, il faut garder à l'esprit que pour les bdir officielles, les fichiers seront conservés 10 ans.
Merci avant de déposer des données :- de vérifier le volume des données
- d'alerter le CTIG par si le volume semble conséquent (par exemple s'il le volume est relativement plus important que le volume de la BDIR concernée, ou s'il dépasse 20Go)
- par défaut de compresser au maximum ces données (ne pas compresser uniquement s'il est important que les données soient accessibles en direct)
Les fichiers permanents ne sont pas archivés car permanents et toujours disponibles.
Les descriptions SAS ne sont pas archivées car les BDIR n+1 sont compatibles avec les descriptions n et inversement.
Données provisoires
Les données provisoires généralement utilisées pour les vérifications, sont dans des répertoires "prov" portant le meme nom que les répertoires définitifs, suivi de _prov
(par exemple /bdir/bovins/commun/donnees_bn_prov ou /bdir/bovins/iboval/retour_ferme_prov)
Il existe aussi le répertoire bdir_ech pouvant servir à l'échange de fichiers tests entre ctig et indexeurs
Toutes ces données sont conservées 6 mois en ligne, puis supprimées.
Particularités
Quelques bdir ne sont pas utiles à l'indexation mais sont plutôt du type infocentre (extractions de données), ces bdir ont soit un statut officiel (conservées 3 ans puis supprimées et archivées), soit non officiel (conservées 6 mois puis supprimées) :- /bdir/ovins/moleculaire/donnees_bn : non officiel
- /bdir/ovins/ovall/donnees_bn : non officiel
- /bdir/ovins/ovall/bilans : officiel
Infosnig¶
Infocentre des SNIG pour l'IDELE accessible à partir de dga2 et dgaprod.
En cas de problème sur l'infosnig, contacter ctig.systeme@dga.jouy.inra.fr
L'infosnig est une base de données à destination de l'IDELE qui contient des fichiers issus des systèmes nationaux de gestion des données
C'est un infocentre : les données de référence restent dans les systèmes d’informations nationaux.
Données¶
Pour toute demande d'accès, contacter :
infosnig : louise.marguin@idele.fr sophie.mattalia@jouy.inra.fr ??
Voir la partie cadre technique pour les descriptions techniques de l'organisation des données de l'infosnig.
Voir les outils mis à disposition sont disponibles depuis toutes les plateformes qui accèdent a l'infosnig.
Suppression¶
Pour les extractions hebdomadaires, 2 versions sont conservées (partie sig)
Les autres fichiers sont conservées 2 ans en ligne puis supprimés (partie stats_cl, meilleures carrieres)
Cadre technique¶
Organisation des fichiers¶
Les fichiers sont stockés sous forme de fichiers plats dans une arborescence Unix prévue à cet effet.
On décrit dans cette partie les conventions et règles qui s’appliquent à tous les fichiers de cette arborescence.
Les fichiers sont regroupés en ensembles cohérents (extraits en même temps, calculés en même temps ou par les memes personnes ...).
Cette cohérence est traduite par l’appartenance à un même répertoire :- tous les fichiers d’un même répertoire sont créés dans la même unité de temps
- tous les fichiers d’un même répertoire ont les mêmes droits d’accès
Les sous répertoires « héritent » par défaut des caractéristiques du répertoire parent.
Les droits sont définis et gérés par l'équipe système du CTIG. Il ne faut pas essayer de les modifier car cela casse les droits.
Les deux premiers niveaux de rangement sont l’espèce puis la base ou le type de production. L’organisation retenue est la suivante :
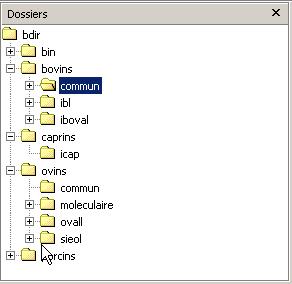
Ensuite l'organisation est la suivante
Les données issues des processus d’indexation officielle sont placées dans des dossiers spécifiques :
Le tableau suivant donne la liste des répertoires créés pour la partie « retour indexation des ovins laits »
Nom dossier Contenu Qui crée à l’intérieur Qui utilise
eval_morpho_retour Valeurs génétiques calculées, paramètres génétiques ... de l’indexation morphologie Indexeur Toute personne autorisée
eval_morpho_pl Valeurs génétiques calculées, paramètres génétiques ... de l’indexation laitière Indexeur Toute personne autorisée
eval_retour_diffusion Index publiés Indexeur Toute personne autorisée
Documentation¶
Un fichier fera l’objet d’une documentation qui rassemblera les informations nécessaires à son utilisation :
Nom du fichier : le nom de fichier est unique. Un nom de fichier fait toujours référence au même ensemble de données (population et variables). Ainsi, par exemple, si un fichier generalogies.txt a été créé dans une arborescence, on ne pourra pas avoir d’autres fichiers du même nom avec un contenu différent à un autre endroit de l'arborescence. Il peut y avoir cependant plusieurs fichiers de descriptions identiques par exemple un fichier animrace.txt par race.
Population : La description de la population du fichier
Contenu : la description du contenu du fichier
la plupart des informations utiles seront rassemblées dans un tableau comme celui-ci :
| Nom variable (1) | type (2) | Obl/Fac/Clé | Libellé (3) | Origine (4) | Commentaires (5) |
|---|---|---|---|---|---|
| ANIM | Char(14) | P | N° National animal | BOINAR | =COPAIP+NUNATI |
| CORABO | Char(2) | O | Race Bovin | BOVIDE | |
| RACINDX | Char(2) | O | Race d indexation | (1) (6) | |
| .... | |||||
| DAINAR | Date | F | Date IA | BOINAR | DAINAR |
(1) si CORABO appartient à [‘66’,’46’,’66’] : RACINDX = CORABO, sinon RACEINDX = '00'
On applique les règles suivantes :- Numeros animaux et cheptels sont concaténés pour aciliter l'utilisation
- Un nom de variable sert autant que possible à nommer une notion et une seule.
- Si une variable est reprise telle quelle de la base nationale, on ne changera pas son nom. Si elle fait l'objet d'une transformation (changement d’unité, recodification ...), on ne reprend pas le nom de la base nationale, ainsi :
- la variable DAINAR, issue directement du SIG Bovins sans transformation, garde son nom
- ANIM, qui est la concaténation de COPAIP et NUNATI a un nom qui n’est pas utilisé dans la base nationale.
- O : obligatoires, l’utilisateur s’attend à la trouver toujours renseignée avec une valeur significative (noté O)
- F : facultatives, la variable peut être soit renseignée avec une valeur significative soit réputée inconnue. Cela permet en particulier de distinguer une valeur de 0 d’une valeur inconnue
- P : primaire (et donc obligatoire), si elle fait partie de la clé primaire du fichier. Si n variables VAR1, ..., VARn sont en clé primaire d’un fichier, on ne trouvera dans celui-ci qu’une ligne pour un n-uplet donné de valeurs de VAR1, ..., VARn. Si une clé primaire est définie sur un fichier, celui-ci est trié selon cette clé primaire , dans l’ordre des colonnes de la clé.
Un modèle pseudo-relationnel¶
Pour représenter les données, on utilise un modèle relationnel simplifié. Les données sont organisées sous forme de fichier avec un nombre de variables fixe. Les 4 lactations d’une vache sont par exemple stockées sous forme de 4 lignes.
| N° National | N° Lactation | Date Début | Lait 305 jours |
|---|---|---|---|
| FR0598005412 | 1 | 2002-02-02 | 8000 |
| FR0598005412 | 2 | 2003-03-08 | 9875 |
| FR0598005412 | 3 | 2004-03-04 | 10544 |
| FR0598005412 | 4 | 2005-06-24 | 7555 |
| FR7905005425 | 1 | 2004-10-15 | 4524 |
| FR7905005425 | 2 | 2005-10-01 | 5155 |
Les données sont sous forme d’un fichier plat de type ascii.On applique les conventions suivantes :
- les lignes sont séparées par les caractères de fin de ligne « CRLF » sous windows ou « LF » sous Unix
- les caractères sont ceux permis par la norme ISO8859-1 (celle de dga2) : les guillemets (“) et les apostrophes (‘) sont des caractères comme les autres
- les champs sont séparés par des ‘;’
- les champs ne doivent pas contenir de ‘;’ ou de caractères de fin de ligne, ni le le caractère hexadécimal ‘00’
- le dernier champ d’un enregistrement se termine par le caractère de fin de ligne
- le nombre de champs est constant dans le fichier
- la première ligne du fichier correspond à la première ligne de données
- un champ vide (variable inconnue) est indiqué par deux points-virgules accolés.
- si le dernier champ est vide, on l’indique en accolant ‘;’ et fin de ligne
L’évolution du contenu des fichiers pourra se faire :
- par changement de nom (si la description devient très différente)
- par changement du n° de version de la description du fichier (ajout de variables par exemple, obligatoirement en derniere position).
Outils mis à disposition¶
En cas de problème sur l'utilisation des outils, contacter ctig.systeme@dga.jouy.inra.fr .
Les outils en lignes de commande peuvent être appelé directement en ajoutant le chemin /bdir/bin dans le chemin (variable PATH) dans le fichier de configuration de votre compte .profile
N'hésitez pas à ajouter ici vos remarques ou suggestion d'outils sur la BDIR : ...
Macros SAS de lecture/écriture de fichiers¶
Pour chaque fichier d’une BDIR ou de l'infosnig, l’utilisateur autorisé peut utiliser une macro SAS de lecture ou d'écriture de fichier.
Les macros permettent de lire ou un fichier dans l'infocentre, ou en dehors de l'infocentre.
Si le fichier n'est pas dans l'infocentre, il faut préciser l'identifiant de la bdir.
Lecture de fichiers (bdir_lec)
Paramètres :
- Nom du fichier que l'on veut lire. Si l'on ne précise pas de nom de fichier la macro va essayer de trouver le dernier fichier disponible à partir de id_bdir et id_fichier : ceci n'est pas conseillé pour des chaines de routine
- id_bdir = identifiant de la bdir ou de l'infosnig ( ex : /bdir/bovins/commun ou /infosnig/index/index_bl_definitifs). Il n'est pas obligatoire de préciser l'identifiant si le fichier est dans l'infocentre
- id_fichier = identifiant du fichier lu (ex : animal), tel que le fichier est connu dans l'infocentre, sans le suffixe (.txt). Ceci permet de lire un fichier en dehors de la bdir et dont le nom est différent
- label (O=oui, N=non - valeur par défaut) = témoin facultatif si on veut que SAS prenne en compte les labels de la description
- firstobs = premier enregistrement a prendre par SAS : positionne firstobs= dans l'ordre infile
- obs = nombre d'enregistrements à lire par SAS, positionne obs= dans l'ordre infile
Exemple de lecture d'un fichier en BDIR :
options print;
data donnaiss;
%bdir_lec(/bdir/bovins/iboval/donnees_bn/ex_2011_12_16/lim/tous/donnaissV2.txt, label=O, firstobs=10, obs=100);
Exemple de lecture d'un fichier en local d'un nom connu dans l'infocentre :
*options mprint mlogic symbolgen implmac;
data test;
%bdir_lec(ibltaur.txt, id_bdir=/infosnig/index/taureaux_bl, obs=100);
proc print;
run;
Exemple de lecture d'un fichier en local d'un nom inconnu dans l'infocentre :
data test;
%bdir_lec(mesanimaux.txt, id_bdir=/bdir/bovins/commun, id_fichier=animal, obs=100);
remarque : on peut intégrer une "macro variable" dans le nom de fichier ( exemple "&MONTRAV/animal.txt"). Dans ce cas, le nom de fichier doit être spécifié entre des doubles quotes.
Exemple de lecture du dernier fichier animal :
data animal;
%bdir_lec(id_bdir=/bdir/bovins/commun, id_fichier=animal, obs=100);
remarque: en cas de probleme de la commande, essayer la commande cd /bdir/bovins/commun ; find . , pour voir si elle répond bien et le cas échéant contacter ctig.systeme@dga.jouy.inra.fr
remarque: il est possible de préciser plus finement la partie de la bdir concernée (id_bdir), ainsi que l'identifiant du fichier tel qu'il est connu dans une extraction donnée
Exemple de lecture du dernier fichier pat210V2 d'une bdir charolaise :
data pat210;
%bdir_lec(id_bdir=/bdir/bovins/iboval/donnees_bn, id_fichier=cha/sig/pat210V2, obs=100);
Exemple de lecture du dernier fichier animrace.txt en race 66 :
data animal;
%bdir_lec(id_bdir=/bdir/bovins/commun, id_fichier=r66/animrace, obs=100);
Ecriture de fichiers (bdir_ecr)
Paramètres :
- Nom du fichier que l'on veut écrire
- id_bdir = identifiant de la bdir ou de l'infosnig ( ex : /bdir/bovins/commun ou /infosnig/index/index_bl_definitifs). Il n'est pas obligatoire de préciser l'identifiant si le fichier est dans l'infocentre
- id_fichier = identifiant du fichier lu (ex : animal), tel que le fichier est connu dans l'infocentre, sans le suffixe (.txt). Ceci permet d'ecrire un fichier en dehors de la bdir et dont le nom est différent
Exemple d'écriture d'un fichier en BDIR :
%bdir_ecr(/bdir/bovins/iboval/donnees_bn/ex_2011_12_16/lim/tous/donnaissV2.txt);
Exemple d'écriture d'un fichier en local d'un nom connu dans l'infocentre :
%bdir_ecr(donnaissV2.txt, id_bdir=/bdir/bovins/iboval);
Exemple d'écriture d'un fichier en local d'un nom inconnu dans l'infocentre :
%bdir_ecr(donnees_naissance.sas, id_bdir=/bdir/bovins/iboval, id_fichier=donnaissV2);
Remontée de généalogies¶
Ce programme permet de remonter les généalogies à partir d'un fichier contenant une liste d'animaux. Il s'appuie par défaut sur les derniers fichiers de généalogie extraits en BDIR.
En bovins, il peut fonctionner pour une race donnée.
ATTENTION : Le programme n'est pas prévu pour fonctionner à partir d'une grosse liste d'animaux. Merci de limiter les accès à quelques animaux (ou quelques milliers au maximum)
Deux paramètres obligatoires (dans l'ordre suivant) :- bdir : bovins, sieol ou ovall
- nom du fichier contenant la liste des animaux à prendre en compte
- pour les bovins : FR0100003179
- pour ovall (identifiant informatique) : D000000010
Options possibles (à préciser après les paramètres obligatoires) :
- -g <n> : nombre de générations à remonter (si -g 3, on remonte jusqu'aux grands parents)
- -f <nomfichier> : nom du fichier à utiliser à la place du fichier en bdir
- -r <race> : utilise le fichier animrace.txt (uniquement pour bovins)
- -p : permet la suppression des informations concernant les parents des animaux de la dernière génération
- -l <nomFichierLog> : fichier de log
Exemples :
remontee_genea bovins liste.txt remontee_genea ovall liste_ovins.txt -g 2 -p > liste_ovins_avecparents.txt remontee_genea sieol listegenea.txt -g 3 -p > resgenea_avec parents.txt
Récupération de lignes¶
Ce programme permet de sélectionner toutes les lignes d'un fichier dont une ou plusieurs colonnes, définies par l'utilisateur, contiennent au moins une des valeurs listées dans un autre fichier.
Trois paramètres obligatoires (dans l'ordre suivant) :- nom du fichier contenant la liste des valeurs recherchées (avec une valeurs par ligne)
- nom du fichier dont on veut extraire des lignes : le séparateur entre les colonnes, dans le fichier, par défaut est le point-virgule
- le ou les numéros de colonnes sur lesquelles la recherche doit être effectuée (si plusieurs colonnes, séparer les numéros de colonnes par un tiret (-), par exemple si on veut rechercher une valeur dans les colonnes 3 ou 9, on écrit 3-9. Les colonnes doivent être indiquées dans l'ordre (écrire 3-9 et pas 9-3).
Options possibles (à préciser après les paramètres obligatoires) :
- 4ème paramètre permettant de définir un autre séparateur que le point-virgule, par exemple '|' ou ' '
Exemple 1:
echo "22618011146" > animaux.txt echo "29231610067" >> animaux.txt echo "10530670094" >> animaux.txt recup_lignes animaux.txt /bdir/ovins/ovall/donnees_bn/ex_2011_05_08/bn_tzred.txt 5
Exemple 2:
echo "23" > race23.txt recup_lignes race23.txt /bdir/bovins/commun/donnees_bn/ex_2011_05_06/animal.txt 4-5-6 > animauxderace23ouavecparentderace23.txt
Ajout d'une entete a un fichier¶
Ce programme permet d'ajouter une lignes d'entete avec le nom des colonnes en première ligne d'un fichier.
Ceci permet de visualiser facilement un fichier avec Excel par exemple (Attention : lorsque l'on ouvre un fichier avec Excel, Excel par défaut n'affiche par les 0 devant les nombres, et peut aussi modifier le format des dates). A partir des fichiers crees, on peut aussi cree un vrai fichier Excel a partir du script Excel.
Trois paramètres obligatoires (dans l'ordre suivant) :
- nom du fichier : nom du fichier auquel on veut ajouter une entete
- id_bdir : identifiant du répertoire auquel se rattache le fichier : par exemple /bdir/ovins/ovall ou /infosnig ou /bdir/bovins/ibl
- id_fichier : identifiant du fichier (sans l'extension)
(Les deux derniers paramètres permettent à l'outil de retrouver la dernière description du fichier, dans le répertoire id_bdir/descriptions/id_fichier*.sas)
Option possible (à préciser après les paramètres obligatoires) :- -l : la ligne qui suit les noms de colonnes contient les labels
- -f : la premiere ligne contient les formats SAS (option interessante pour l'outil excel)
Exemple 1:
entete /bdir/bovins/ibl/retour_poly/t1110/morpho/r66/index_morpho_mal.txt /bdir/bovins/ibl index_morpho_mal66 > index_morpho_mal66_t1110.csv
Exemple 2:
entete /infosnig/index/taureaux_bl/ex_2011_05_10/ibltaur.txt /infosnig ibltaur -l -f > ibltaur.csv
Exemple 3:
head -n 5 /bdir/ovins/ovall/donnees_bn/ex_2011_05_08/bn_tzred.txt > bn_tzred_5premiereslignes.txt entete bn_tzred_5premiereslignes.txt /bdir/ovins/ovall bn_tzred
Exemple 4:
echo "D000000010" > animal.txt remontee_genea ovall animal.txt > animal_avecgenealogie.txt entete animal_avecgenealogie.txt /bdir/ovins/ovall bn_tzred > animal_avecgenealogie.csv rm animal.txt rm animal_avecgenealogie.txt
Création de fichier Excel¶
Ce programme permet de créer un fichier excel à partir de plusieurs fichiers csv, chaque onglet correspondant a un fichier csv. Il fonctionne bien en particulier lorsque les fichiers sont créés par le script entete ci-dessus.
Au moins 2 paramètres obligatoires (dans l'ordre suivant), mais plusieurs paramètres sont possibles :- nom du fichier Excel : nom du fichier excel généré par le programme
- nom du premier fichier csv à prendre en compte
- nom du deuxième fichier csv à prendre en compte
- etc
- option -f : cela signifie que la première ligne contient les formats SAS, ce qui permet à l'outil de formater les colonnes dans Excel
- option -l : cela signifie que la ligne qui suit les noms de colonnes contient les labels
La première ligne du fichier Excel contient les noms des colonnes. Les formats et les labels sont repris dans les commentaires de la première ligne.
Tous les fichiers utilises doivent avoir le même format, le mieux est de les créer avec entete et les options -f -l, et de générer le fichier excel avec les mêmes options
Exemples :
excel mesanimaux.xlsx animal.csv pat120.csv pat210.csv -f -l
Realisez vos propres outils¶
A l'aide de différentes commandes, vous pouvez realiser vos propres outils.
Parlez en ici. Cette page est un wiki que vous pouvez modifier facilement.
Exemple¶
Prenons l'exemple de la realisation d'un script permettant de récupérer dans un fichier excel toutes les données iboval concernant des animaux nés sur une campagne dans un cheptel ainsi que leurs parents sur une génération :
code de recup_cheptels :
echo Script permettant de recuperer dans un fichier excel toutes les donnees iboval echo concernant des animaux nes sur une campagne echo dans un cheptel ainsi que leurs parents sur une generation echo Parametre race = $1 echo Parametre extraction bdir aaaa_mm_jj = $2 echo Parametre campn = $3 echo Parametre cheptel = $4 echo Parametre nomFichierExcel en sortie = $5 echo Parametre adresse mail = $6 echo ------------------------------------------ echo Recuperation des animaux nes dans $4 sur la campagne de naissance $3 echo $4 > cheptel.txt;echo $3 > campn.txt recup_lignes cheptel.txt /bdir/bovins/iboval/donnees_bn/ex_$2/$1/tous/donnaissV2.txt 18 > donnaissV2_cheptel.txt recup_lignes campn.txt donnaissV2_cheptel.txt 20 > donnaissV2_cheptel_campn.txt perl -laF\; -ne 'print "$F[1]"' donnaissV2_cheptel_campn.txt > animaux_concernes.txt rm cheptel.txt donnaissV2_cheptel.txt campn.txt donnaissV2_cheptel_campn.txt echo Recherche des parents de ces animaux remontee_genea bovins animaux_concernes.txt -g 2 > animal_animaux_et_parents.txt perl -laF\; -ne 'print "$F[0]"' animal_animaux_et_parents.txt > animaux_et_parents.txt rm animal_animaux_et_parents.txt animaux_concernes.txt echo Recuperation des lignes iboval à partir des fichiers /bdir/bovins/iboval/donnees_bn/ex_$2/$1/tous/ recup_lignes animaux_et_parents.txt /bdir/bovins/iboval/donnees_bn/ex_$2/$1/tous/donnaissV2.txt 2 > donnaissV2.txt recup_lignes animaux_et_parents.txt /bdir/bovins/iboval/donnees_bn/ex_$2/$1/tous/pat120V2.txt 2 > pat120V2.txt recup_lignes animaux_et_parents.txt /bdir/bovins/iboval/donnees_bn/ex_$2/$1/tous/pat210V2.txt 2 > pat210V2.txt recup_lignes animaux_et_parents.txt /bdir/bovins/iboval/donnees_bn/ex_$2/$1/tous/peseesV2.txt 2 > peseesV2.txt recup_lignes animaux_et_parents.txt /bdir/bovins/iboval/donnees_bn/ex_$2/$1/tous/pointsevV2.txt 2 > pointsevV2.txt echo Creation du fichier final et envoi par mail entete donnaissV2.txt /bdir/bovins/iboval donnaissV2 -l -f > donnaissV2.csv entete pat120V2.txt /bdir/bovins/iboval pat120V2 -l -f > pat120V2.csv entete pat210V2.txt /bdir/bovins/iboval pat210V2 -l -f > pat210V2.csv entete peseesV2.txt /bdir/bovins/iboval peseesV2 -l -f > peseesV2.csv entete pointsevV2.txt /bdir/bovins/iboval pointsevV2 -l -f > pointsevV2.csv rm donnaissV2.txt pat120V2.txt pat210V2.txt peseesV2.txt pointsevV2.txt excel $5 donnaissV2.csv pat120V2.csv pat210V2.csv peseesV2.csv pointsevV2.csv -l -f rm animaux_et_parents.txt donnaissV2.csv pat120V2.csv pat210V2.csv peseesV2.csv pointsevV2.csv zip $5.temp.zip $5 uuencode $5.temp.zip $5.zip | mail -s "Extraction iboval $2 des animaux $1 nes dans $4 sur la campagne $3 et de leur parents" $6 echo Script termine
L'appel se ferait de la façon suivante
recup_cheptels rou 2011_12_30 2011 FR44202026 FR44202026.xlsx monnom@adressemail.fr
Notes¶
(1) C’est le nom, ou code de la variable
(2) Codification du type de variable))
(3) Libellé, relativement court, que l’on peut afficher dans un outil de consultation))
(4) Quand l’origine de la donnée est sans ambiguïté (colonne d’une table de la base de données nationale) : on indique le code de la table))
(5) Constitution de la donnée :
- colonnes d’origine
- algorithme
- utilisation de la donnée : unité, valeurs possibles
))
(6) Quand l’origine des données n’est pas immédiate, on fait un renvoi à un paragraphe ou on décrit la constitution de la variable))