Cluster dga11¶
- Cluster dga11
- Présentation du cluster du CTIG
- Connexion au cluster
- Organisation espace disque
- L’ordonnanceur SGE
Présentation du cluster du CTIG¶
Caractéristiques du cluster¶
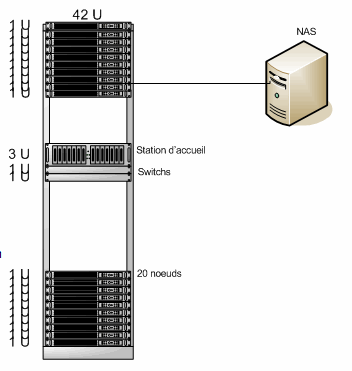
• Cluster SGI Altix XE340
• 44 nœuds de calcul et un nœud frontal
• Interconnexion gigabit ethernet
• 2 switchs 24 ports
• 2 switchs 48 ports
Station d’accueil¶
• Altix XE 270 avec alimentation redondante
• 2 Processeurs Intel Xeon 4 core 5620 2.4 Ghz
• 12 Go de mémoire DDR3
• 2 disques internes SATA II 250 Go, 7200 trs/min
• 4 disques internes SAS 300Go
• 6 emplacements disques
Nœuds de calculs¶
• 40 nœuds de calcul Altix XE 340 + 4 nouveaux noeuds
• 20 nœuds 48Go de RAM
• 20 nœuds 96Go de RAM
• 4 nœuds 256 Go de RAM
• 480 cœurs de 2.66 GHz équipés de 4 Go de RAM chacun + 128 cœurs ( 4 x 2 processeurs Sandy Bridge 8 cœurs - avec hyperthreading donc 16 threads )
• Processeur Intel Xeon 6 core 5650
• 2 Disques SAS 300 Go et 600 Go, 15000 trs/min
• Interconnexion gigabit ethernet
Connexion au cluster¶
Demande de compte¶
L'accès au cluster se fait en cas d'un besoin de parallélisation important. L’ouverture d’un compte sur le cluster dga11 se fait dans le cadre d’un projet.
Pour se connecter sur le cluster et soumettre des jobs il faut au préalable faire une demande d’ouverture de compte au CTIG.
Ligne de commande (SSH)¶
La station d’accueil du cluster se nomme dga11 : elle est accessible par l’adresse dga11.jouy.inra.fr ou via son adresse IP 193.54.97.152
Pour se connecter utiliser un client SSH tel que PuTTY sous Windows, ou SSH sous linux.
ssh user@dga11.jouy.inra.fr
Votre mot de passe vous est demandé. Vous arrivez ensuite dans votre répertoire personnel.
Connexion graphique¶
Pour se connecter au bureau graphique GNOME il faut utiliser un client X2GO.
Organisation espace disque¶
Tous les utilisateurs ont un répertoire personnel sauvegardé situé dans /home qui contient leurs fichiers de configuration.
Un /travail est accessible de la station de travail et des nœuds du cluster, ce n'est pas le même que celui accessible par dga12. Il est situé sur une baie NAS, il est accessible par NFS. Il est ouvert à tous les utilisateurs du cluster. Il n'est pas sauvegardé.
D’autres parts vos répertoires habituels sur les NAS sont accessibles en lecture/écriture depuis chaque nœud et sur la station d’accueil.
En fin de calcul ne pas oublier de recopier les fichiers de sortie sur vos répertoires habituels et de faire le ménage dans les répertoires de travail du cluster. Il n'y a pas de nettoyage automatique sur le /travail du cluster.
La commande : df -h /travail permet de connaitre la taille et l'occupation des file-systems :
Filesystem Size Used Avail Use% Mounted on
192.168.200.102:/vol/travail 2.0T 1.9T 114G 95% /travail
L’ordonnanceur SGE¶
Présentation de SGE¶
L’ordonnanceur utilisé pour soumettre des jobs de calcul sur le cluster du CTIG est SGE (Sun Grid Engine), c’est un logiciel open source.
Il a été mis en place plusieurs files d'attentes (queues) suivant la durée maximum d'exécution du job : ainsi, plus le job sera court et plus la priorité sera élevée. Actuellement le cluster dispose de 480 cœurs qui permettent de faire tourner 480 jobs simultanément. Il n’est possible dans la configuration actuelle que d’utiliser un cœur par job (sauf en lançant des jobs en parallèles).
L’objectif des files est de répondre à la majeure partie des besoins tout en optimisant l’utilisation du cluster.
Attention : tout job lancé hors SGE est supprimé sans préavis
Voici les files d’attentes disponibles, le nombre de cœurs disponible indiqué est pour une utilisation de 4G de mémoire :
| Nom de la file | Durée maximum du job* | Nombre de cœurs disponibles (si les autres files ne sont pas utilisées) |
|---|---|---|
| longq | 48h | 120 ou 240-N avec N>120 |
| unlimitq | illimité | 30 |
| workq | 2h | 480 –N / limité à 440 par util. |
| bigmem | illimité | 368 |
*Durée maximum d’utilisation du processeur
N : Nombre de jobs actifs
Les jobs en trop sont mis en attente.
Dans la classe bigmem, 128 threads sont disponibles avec 250 Go de mémoire et 240 sont avec 90 Go de mémoire.
La capacité physique de la mémoire de ces nœuds est 256 Go (ou 96). 6 Go reste réservé pour le système d'exploitation, une limite à 250 Go (ou 90) à été mise en place. Cependant, il peut arriver que le système d’exploitation prenne plus de 6 Go, dans ce cas les jobs qui demandaient 250 Go restent bloqués, il faut alors contacter ctig.systeme@dga.jouy.inra.fr ou demander moins de mémoire.
Soumettre un job¶
En ligne de commande :
qsub - submit a batch job to Sun Grid Engine. qsh - submit an interactive X-windows session to Sun Grid Engine. qlogin - submit an interactive login session to Sun Grid Engine. qrsh - submit an interactive rsh session to Sun Grid Engine. qalter - modify a pending batch job of Sun Grid Engine. qresub - submit a copy of an existing Sun Grid Engine job.
Exemple pour un job simple :
1 - Il faut préparer un fichier (script) contenant la (ou les) ligne(s) de commande
2 - Vos fichiers de sortie doivent être impérativement dirigés vers l'espace disque /work
3- Il faut impérativement préciser la quantité de mémoire à utiliser avec –l h_vmem= sinon il vous sera alloué 4Go maximum par job.
4 - Soumettre le job avec la commande de soumission (qsub)
Voici un exemple de script de soumission (il est aussi possible de lancer des jobs en interactif):
monscript.sh
#!/bin/sh #$ -o /work/.../output.txt #$ -e /work/.../error.txt #$ -q longq #$ -M mon_email@inra.fr #$ -m bea #$ -l h_vmem=3G # Mon programme commence ici : blastall -d swissprot -p blastx -i /work/.../z72882.fa
Toute ligne commençant par #$ indique une option à exécuter par sge.
-l h_vmem=8G : pour spécifier à l'ordonnanceur l'allocation de 8Go de mémoire pour l'exécution
de ce job.
-q queue_name : spécifier le nom de la queue
-o output_filename : redirection de la sortie standard
-e error_filename : redirection de la sortie d'erreur
-M mon_adresse@mail : si un problème survient pendant l'exécution, un mail est envoyé à cette adresse.
-m bae : quand ce mail doit être envoyé (b : begin, a : abort, e : end)
-N job_name : pour donner un nom à son job
Pour soumettre :
qsub monscript.sh
Alternativement, vous pouvez ne faire apparaître que les lignes de commandes dans le script et indiquer les options à l’appel de qsub.
Soit qsub –l h_vmem=3G –q longq –M mon_email@inra.fr –m bea Monscript.sh
Avec l’interface graphique ce sont les mêmes commandes. Pour lancer l’interface taper « qmon ».
Suivre l’exécution d’un job¶
Utiliser la commande qstat dont voici quelques options :
qstat : liste les jobs de tous les utilisateurs en cours
qstat -u user : donne les informations uniquement sur l'utilisateur
qstat -j job_id : détail sur un job en particulier (numéro id attribué par SGE)
qstat -s r : donne uniquement les jobs avec le status r(unning)
qstat -f : visualise les jobs en cours par file et par nœud
La commande qmon permet de donner le même type d'information via une interface graphique.
Suivre l’exécution avec Ganglia :
En se connectant (depuis dga11) sur http://dga11.jouy.inra.fr/ganglia/ à l’aide d’un navigateur, vous pouvez obtenir une vue synthétique de l’état du cluster. Les informations essentielles apparaissant sur cette interface sont le nombre nœuds et le nombre de jobs potentiels présents sur le cluster. Le nombre de jobs en cours d’exécution sont également représenté à l’aide d’une ligne bleu, tandis qu’une aire grisée indique le load average de la plateforme. Note importante lors d’une utilisation normale des ressources la courbe du nombre de processus en cours d’exécution et l’aire tracée par le load average doivent concorder. En cas contraire, le script en cours d’exécution devra être repensé.
Obtenir de l’information sur un job terminé¶
Utiliser la commande qacct :
qacct -j job_id : donne les informations sur un job en particulier.
Tuer un job¶
qdel -j job_id : tue un job en particulier
qdel -u user : tue l'ensemble de mes jobs
On ne peut pas tuer les jobs d’un autre utilisateur.